Генератор адресов команд
Генератор адресов команд
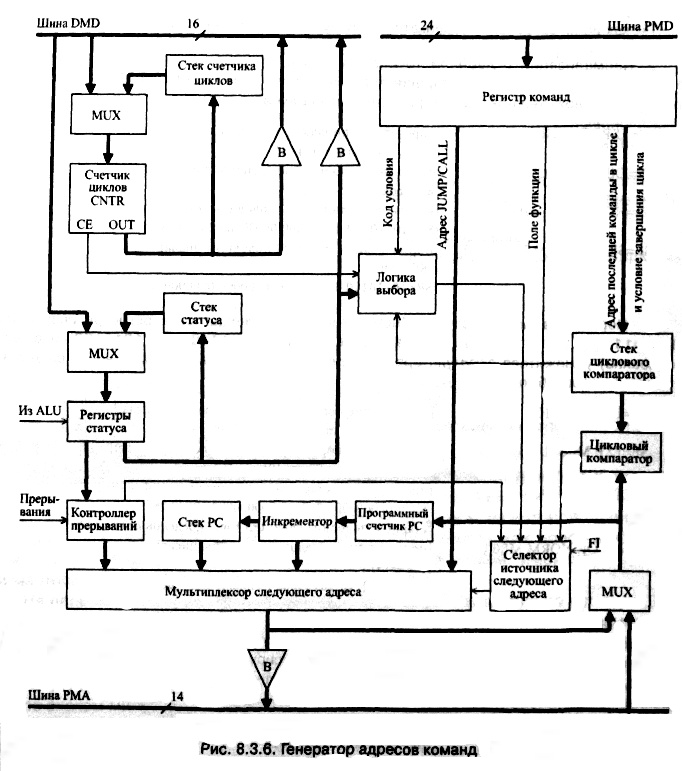
Назначение и состав. Генератор адресов команд (Program Sequencer— PS) формирует последовательность адресов, обеспечивая гибкий контроль выполнения программы.
В состав генератора входят следующие блоки (рис. 8.3.6):
? регистр команд, хранящий код исполняемой команды;
? программный счетчик PC , инкрементор и стек PC;
? счетчик циклов CNTRи его стек;
? цикловый компаратор (Loop Comparator ) и его стек;
? контроллер прерываний;
? регистры статуса и стек статуса;
? логика выбора, селектор источника следующего адреса и мультиплексоры.
- Принцип формирования следующего адреса
- Программный счетчик и его стек
- Цикловый компаратор и его стек
- Контроллер прерываний
- Последовательность обработки прерываний
- Конфигурирование прерываний
- Задержка при обработке прерываний
- Регистр статуса стека SSTAT (только для чтения)
- Регистр арифметического статуса ASTAT
- Регистр режима и статуса процессора MSTAT
- Стек статуса
- Назначение и состав
- Линейная адресация
- Адресация по модулю
- Адресация с изменением порядка бит на обратный
- Возможности портов
- Состав и особенности работы последовательного порта
- Передача
- Кадровые сигналы
- Автобуферизация
- Таймер
- Назначение и состав
- Принцип работы
- Работа с HIP
- Метод опроса
- Работа с прерываниями
- Режим перезаписи HDR –регистров
- Прерывания от HIP
- Начальная загрузка внутренней памяти с использованием HIP
Принцип формирования следующего адреса
В процессе выполнения команды процессором логика генератора адресов формирует адрес следующей команды. Источником адреса могут служить (рис. 8.3.6):
? программный счетчик (ProgramCounter— PC) при последовательном выполнении команд программы;
? стек PC программного счетчика при возврате из подпрограммы или из обработки прерывания;
? регистр команд при безусловном переходе;
? контроллер прерываний при обработке прерывания.
К источнику адреса можно также отнести индексные регистры I0–I7 генератора адресов данных DAG
На основании данных, извлекаемых из регистра команд и других устройств генератора (см. рис. 8.3.6) логика выбора и селектор выбирают источник адреса следующей команды.
Логика выбора определяет, какая из команд должна выполняться: условная команда (например, переход, вызов подпрограммы) или вычислительная команда. Для этого она контролирует:
? последовательность исполнения команд в цикле, используя значения сигнала СЕ (Count Expire— окончание счета) и условие завершения цикла, находящегося на вершине стека циклового компаратора;
? статусные условия, которые формируются на основании содержимого регистра арифметического статуса ASTATи счетчика циклов CNTR. Условия завершения цикла и статусные условия приведены в табл. 8.4.4.
Программный счетчик и его стек
Программный счетчик PC представляет собой 14–разрядный регистр. Выход счетчика подключен к 14–разрядному инкрементору, который увеличивает на единицу текущее значение счетчика.
Связанный с программным счетчиком стек содержит шестнадцать 14–битных ячеек памяти, в которые заносят данные при выполнении команды циклов DO UNTIL, а также при обработке прерывания.
При обработке прерывания в стек помещается текущее значение счетчика (без инкрементации), чтобы вернутся к выполнению прерванной команды по завершении обработки прерывания.
Для записи и чтения стека можно использовать команды:
TOPSTACK= sreg; {запись в стек} sreg= TOPSTACK; {чтение из стека} NOP;
где sreg— любые регистры данных ALU, MAC, SHIFTERи индексные регистры DAG; NOP
— пустая операция обусловлена тем, что верхнее значение стека считывается с задержкой в один цикл.
Счетчик циклов и его стек.
Счетчик циклов CNTR представляет собой 14–разрядный регистр с автоматической декрементацией (уменьшением на единицу) содержимого после завершения каждого цикла. Перед выполнением циклов счетчик загружается требуемым числом повторений N в беззнаковом формате с 14 младших линий шины DMD. Логика окончания счета СЕ (Count Expire) в начале каждого процессорного цикла проверяет условие окончания циклов, а в конце каждого процессорного цикла уменьшает на единицу содержимое счетчика. Выполнение циклов завершается после того, как содержимое счетчика станет равным единице.
Содержимое счетчика может быть считано на шину DMD
(рис. 8.3.6). При этом два старших разряда 16–разрядного кода заполняются нулями.
Стек счетчика циклов позволяет хранить четыре 14–битных значения, что сопутствует организации вложенных циклов. При выполнении внутреннего цикла в стеке хранится значение счетчика для внешнего цикла.
При загрузке в счетчик нового значения с шины DMD текущее значение счетчика помещается в стек. Если при проверке статуса СЕ выясняется, что число повторений истекло, из стека автоматически восстанавливается занесенное ранее значение счетчика.
Счетчик циклов может быть восстановлен вручную при досрочном выходе из циклов.
Содержимое счетчика циклов не заносится в стек при записи с шины DMD нового значения в двух случаях:
?когда счетчик содержит некорректное значение. Такая ситуация складывается после перезапуска процессора и после проверки условия СЕ при пустом стеке;
?при использовании псевдорегистра (или команды) OWR CNTRдля изменения содержимого CNTR. При записи в OWRCNTR переписывается (но не заносится) в стек содержимое CNTR.
Цикловый компаратор и его стек
Эти средства позволяют выполнять команды DO UNTIL циклов без тактов ожидания. При выполнении команды DOUNTIL:
? в стек компаратора помещаются находящиеся в этой команде 14–разрядный адрес последней команды цикла и 4–разрядное условие завершения цикла (табл. 8.4.4), представляющие в совокупности 18–разрядный элемент. Возможно 4 уровня вложения. При вложении циклов появляется один дополнительный процессорный цикл, необходимый для выполнения самой команды DO UNTIL. Запись и чтение 18–разрядного элемента происходит автоматически;
? в стек программного счетчика помещается выходной сигнал инкрементора программного счетчика PC и адрес первой команды цикла;
? в компараторе циклов сравнивается адрес последней команды цикла с адресом следующей команды. При равенстве адресов компаратор вырабатывает сигнал, информирующий логику выбора адреса следующей команды (см. рис. 8.3.6) о том, что в следующем процессорном цикле исполняется последняя команда цикла.
Продолжение исполнения команды DO UNTIL зависит от последней команды цикла. Рассмотрим три характерных случая.
1. Последняя команда не является командой перехода, вызова подпрограммы, возврата из подпрограммы, IDLE. В этом случае следующая команды выбирается схемой логики выбора, исходя из условия завершения циклов (табл. 8.4.4), находящегося на вершине стека циклов компаратора.
Если условие ложно, следующей командой является первая команда цикла, хранящаяся в стеке программного счетчика PC. Работа в циклах продолжается. Если условие завершения циклов истинно, из стека программного счетчика извлекается занесенное ранее инкрементированное значение PC, представляющее собой адрес первой после завершения циклов команды. Работа в циклах прекращается. Из стека циклов, стека программного счетчика и стека счетчика циклов восстанавливаются старые значения.
2. Последняя команда является командой перехода, вызова подпрограммы, возврата из подпрограммы. Если условие завершения циклов ложно, сохраняется описанная выше последовательность действий для этого случая. Если условие истинно, ни одно из указанных выше действий для этого случая не происходит. Управление передается по адресу перехода, вызова подпрограммы или возврата из подпрограммы.
3. Последней командой является IDLE. В этом случае блокируется действие команды DO UNTIL. Процессор входит в режим ожидания прерывания с пониженным энергопотреблением. После обслуживании прерывания работа в циклах прекращается и начинается исполнение основной программы с команды, расположенной за командой IDLE.
Контроллер прерываний
Контроллер прерываний предназначен для обработки прерываний по вектору прерывания. В качестве примера в табл. 8.3.3 для процессора ADSP–2111 приведены источники и векторы прерывания в порядке уменьшения приоритета.
Адреса векторов прерывания имеют интервал в 4 бита для записи коротких подпрограмм обработки прерываний или адресов длинных подпрограмм. 
Последовательность обработки прерываний
Поступивший от источника запрос на прерывание откладывается до конца выполнения текущей команды. Если прерывание не замаскировано, текущее значение программного счетчика PC, содержащее адрес следующей команды, заносится в стек PC. В стек статуса (рис. 8.3.6) помещается содержимое регистра арифметического статуса ASTAT, регистра режима и статуса процессора MSTAT и регистра разрешения прерываний IMASK в указанном порядке.
После этого из регистра конфигурирования внешних прерываний ICNTL (табл. 8.3.4) в стек статуса загружается флаг разрешения вложенных прерываний (позиция ICNTL.4).
Во время загрузки команды, расположенной по адресу вектора прерывания, процессор выполняет пустую команду NOP. После возврата из процедуры обработки прерывания извлекается содержимое стека PC и статуса, после чего возобновляется исполнение основной программы со следующей команды.
Конфигурирование прерываний
Для этой цели используются:
? пятиразрядный регистр управления прерываниями ICNTL
(табл. 8.3.4), конфигурирующий внешние прерывания. Состояние регистра после сброса не определено;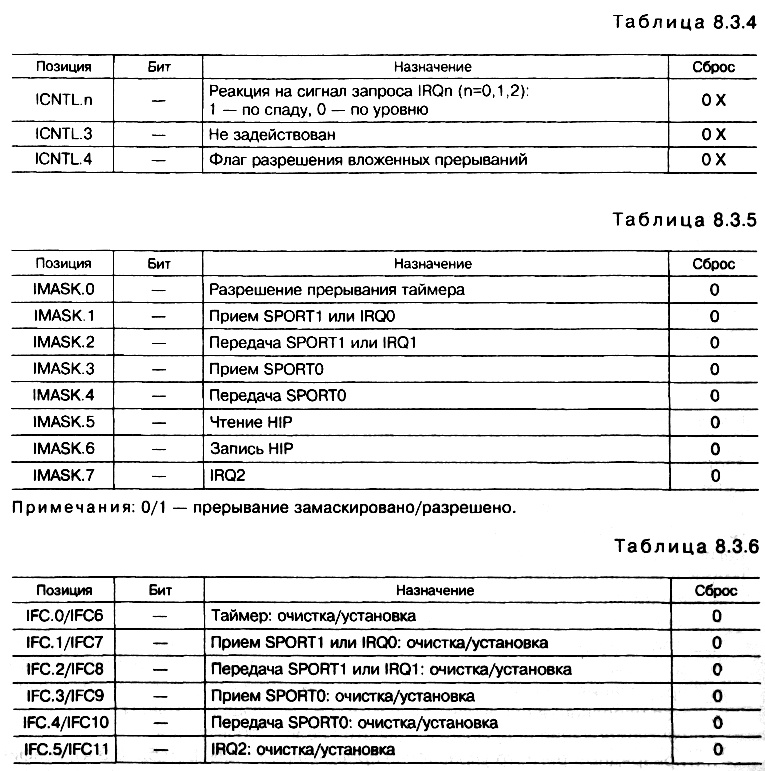
? восьмиразрядный регистр разрешения/маскирования прерываний IMASK(табл. 8.3.5). При входе в подпрограмму обработки прерывания содержимое IMASK автоматически сохраняется в стеке статуса и восстанавливается из стека статуса при выходе из подпрограммы. Содержимое IMASK может быть изменено в самой подпрограмме обработки прерываний. При запрещении вложенных прерываний (ICNTL .4 = 0) содержимое регистра IMASK очищается при входе в процедуру обработки подпрограммы. При разрешении вложенных прерываний (ICNTL.4 = 1) маскируются только прерывания с меньшим или равным приоритетом по отношению к текущему прерыванию. Внешние прерывания, сконфигурированные по спаду (ICNTL.n= 1), в случае их маскирования фиксируются, но не обрабатываются процессором. Зафиксированное прерывание можно программно распознать и обработать;
? доступный только для записи двенадцатиразрядный регистр очистки/установки прерываний (табл. 8.3.6), позволяющий программно очищать и принудительно устанавливать любые прерывания.
Задержка при обработке прерываний
При обработке прерываний IRQn, SPORT k (k = 0,1), HIP существует задержка в три процессорных цикла от времени фиксации прерывания до момента исполнения первой команды подпрограммы. Прерывание от таймера исполняется с задержкой в один процессорный цикл.
Рассмотрим регистры статуса, в которых хранятся флаги, отражающие состояние процессора и биты для установки требуемого режима его работы.
Флаг загружается в ASTATв конце цикла, в котором он был сгенерирован. Действие флага проявляется в следующем цикле. При выполнении команды АЛУ PASS происходит установка флагов AZ AN для данного операнда X или Y и очистка флага АС. При загрузке любого входного и выходного регистров вычислительных устройств процессора с шины DMD состояние флагов остается неизменным.
Регистр статуса стека SSTAT (только для чтения)
Восьмиразрядный регистр SSTAT (табл. 8.3.8) хранит информацию о четырех стеках процессора. Установленный бит в позициях «стек пуст» свидетельствует о том, что с момента сброса процессора число извлечений из данного стека превысило или равно числу помещений в стек. Установленный бит в позиции «переполнение стека» свидетельствует о том, что число помещений в стек превысило число извлечений из стека более чем на глубину стека. При переполнении новые данные в стек не записываются, так как сохраняются старые данные. 
Следует отметить, что в регистре SSTAT могут быть одновременно установлены биты пустоты и переполнения стека. Для очистки регистра следует произвести сброс процессора.
Регистр арифметического статуса ASTAT
Восьмиразрядный регистр ASTAT
(табл. 8.3.7) хранит флаги, формируемые вычислительными устройствами после выполнения текущей команды. 
Регистр режима и статуса процессора MSTAT
Регистр MSTAT(табл. 8.3.9) задает режим работы процессора. В отличие от других статусных регистров содержимое этого регистра может быть изменено с помощью команд управления режимом ENA, DIS.
Например, команда
? ENA BIT_REV активизирует режим реверса бит в DAG1;
? ENA SEC_REC активизирует второй банк регистров ALU, MAC и Shifter;
? DIS SEC_REC активизирует основной банк регистров ALU, MAC и Shifter.
Разрешение режима предоставления шин GO (Grant Out) позволяет процессору выполнить команды из внутренней памяти программ в то время, когда внешняя шина предоставлена другому устройству. Процессор перейдет в состояние ожидания только тогда, когда потребуется доступ к внешней памяти. При выключенном режиме GOпроцессор всегда переходит в состояние ожидания во время предоставления шины другому устройству.
Стек статуса
Автоматически принимает содержимое регистров разрешения/маскирования прерываний IMASK, режима и статуса MSTAT и арифметического статуса ASTATпри входе в процедуру обработки прерывания, так как они могут быть задействованы в подпрограмме. После обслуживания прерывания (при исполнении последней команды RTI подпрограммы) содержимое регистров восстанавливается из стека. Глубина и ширина стека зависит от числа прерываний, поддерживаемых конкретной версией процессора. Загрузить и выгрузить из стека содержимое указанных регистров можно также с помощью команд PUSH STS и POP STS.
Генераторы адресов данных.
Назначение и состав
Генераторы адресов данных (DAG 1 и DAG 2) обеспечивают косвенную адресацию при передаче данных в процессор и из процессора.
Каждый из генераторов адресов данных содержит (рис. 8.3.7):
? четыре 14–разрядных индексных регистра I(I0–I3 в DAG1, I4–I7 в DAG 2) для хранения реальных адресов, по которым производится доступ к памяти в режиме косвенной адресации;
? четыре 14–разрядных регистра модификации М (M0–M3 в DAG1, М4–М7 в DAG2), позволяющие модифицировать следующий адрес путем добавления к I–регистру знакового содержимого М–регистра. Поэтому модифицированный адрес может быть больше или меньше текущего. Регистры I и М могут быть любыми, но должны принадлежать одному DAG;
? четыре 14–разрядных регистра длины L(L0–L3 в DAG1, L4–L7 в DAG2), отличное от нуля содержимое которых задает длину кольцевого буфера при адресации по модулю. При L= 0 реализуется линейная адресация к памяти. Индексы задействованных регистров Lи I должны совпадать, например, L1 и I1;
? логику по модулю, обеспечивающую адресацию по модулю кольцевых буферов;
? мультиплексор MUX, позволяющий выбрать содержимое для загрузки в индексный регистр (см. рис. 8.3.7);
? логику реверса бит (имеется только в DAG
1), предназначенную для изменения порядка бит в адресе на обратный.
Содержимое регистров I и L являются беззнаковыми числами, поэтому при считывании регистров на шину DMD два старших разряда заполняются нулями. Содержимое регистра М считается знаковым, поэтому два старших разряда при Считывании М шину DMD заполняются знаковым расширением.
Линейная адресация
Регистр I должен быть пустым (I= 0). Текущее содержимое индексного регистра I соответствует адресу требуемой ячейки памяти. Адрес следующей ячейки определяется как сумма беззнакового содержимого индексного регистра I и знакового содержимого любого регистра модификации М, принадлежащего тому же генератору адресов данных. Значение суммы через логику по модулю и мультиплексор поступает в индексный регистр для адресации к следующей ячейке (рис. 8.3.7).
Адресация по модулю
В этом режиме адресации отличное от нуля содержимое регистра L задает длину кольцевого буфера. Базовый адрес буфера представляет собой число В = 2n, равное округленному вверх до ближайшей степени n значению L. Например, если I = 6, то базовый адрес В = 23 = 8, так как ближайшая степень n = 3. Таким образом, кольцевой буфер размером L слов располагается по адресам В…В+L–1.
Отметим, что базовым адресом может служить KxB, где K = 1, 2, 3,… При адресации по модулю адрес следующей ячейки памяти определяется как при линейной адресации с учетом того, что его значение А не должно выходит за пределы B…B+L–1.
Поэтому, если В <= I+М <= B+L–1, то А = I+M; I+M < В, тоА= I+M+L; I+M>B+L–1,тоA = I+M–L.
Примеры. 1. Для L0 = 3, В = 4, М0 = 1 пределы адресов кольцевого буфера составляют 4…6. Поэтому согласно приведенным выше соотношениям при начальном значении I0 = 5 генератором адресов данных будет сформирована следующая последовательность адресов: 5, 6, 4, 5, 6, 4, 5,… Первый адрес последовательности соответствует содержимому I0 = 5 в исходном состоянии. Второй адрес последовательности равен I0+М0 = 5+1 = 6. Текущее значение I0 становится равным 6. Так как при вычислении третьего адреса I0+М0 = 6+1 = 7 > 6, его значение равно I0+M0–L0 = 6+1–3 = 4. Подобным образом определяются другие адреса последовательности. 2. Для L0 = 3, В = 4, М0 = –1 пределы адресов кольцевого буфера также составляют 4…6. Однако в этом случае при начальном I0 = 5 генератором адресов данных будет сформирована следующая последовательность адресов: 5, 4, 6, 5, 4, 6, 5,…
Адресация с изменением порядка бит на обратный
Такой режим адресации может быть реализован только в DAG1. Его включение осуществляется установкой бита BIT_REV (позиция MSTAT.1) в регистре режима и статуса. При включенном режиме расположение бит в индексных регистрах I0–I3 и, следовательно, в адресе изменяется на обратный. Изменение порядка бит в адресе на обратный используется в алгоритмах быстрого преобразования Фурье. Последовательный порт.
Возможности портов
Каждый порт SPORTn (n = 0, 1) может:
? обеспечить двунаправленный дуплексный режим обмена информацией по двухпроводной линии, так как имеет независимые секции приема и передачи; использовать внешние и генерировать собственные синхроимпульсы в широком диапазоне частот (от нуля герц);
? поддерживать длину последовательного слова от трех до шестнадцати бит;
? поддерживать два алгоритма аппаратного сжатия информации: по А–закону и u–закону в соответствие со спецификацией CCITT G.117;
? работать в режиме автобуферизации, при котором прерывание генерируется после того, как принят или передан целый блок данных. Последовательный порт SPORT0 поддерживает многоканальный режим, при котором передаваемые данные мультиплексированы на 24 или 32 канала. Последовательный порт SPORT1 обеспечивает такие альтернативные функции как два запроса на прерывание и два флага. Каждая секция (приемная и передающая) SPORTn:
? имеет собственные регистры принимаемых/передаваемых данных в параллельном коде и сдвиговые регистры для приема и передачи данных в последовательном коде. Двойная буферизация секций обеспечивает дополнительное время для обработки данных процессором;
? обеспечивает работу:
• с сигналами синхронизации кадра при приеме и передаче данных и без них;
• с внутренними или внешними сигналами синхронизации;
• с активным высоким или активным низким уровнем кадровых сигналов;
• с нормальным или альтернативным режимом кадровой синхронизации;
• может генерировать прерывания по завершении приема/передачи отдельного слова или целого буфера данных (в режиме автобуферизации).
Состав и особенности работы последовательного порта
В состав SPORTn (n = 0, 1) входят (рис. 8.3.8):
? регистры передаваемых (TXn) и принимаемых (RXn) данных для хранения информации в параллельном коде;
? сдвигающий регистр передатчика и сдвигающий регистр приемника;
? схема компрессии/декомпрессии;
? схема управления и внутренний тактовый генератор. Каждый порт имеет пять интерфейсных выводов (табл. 8.3.10). 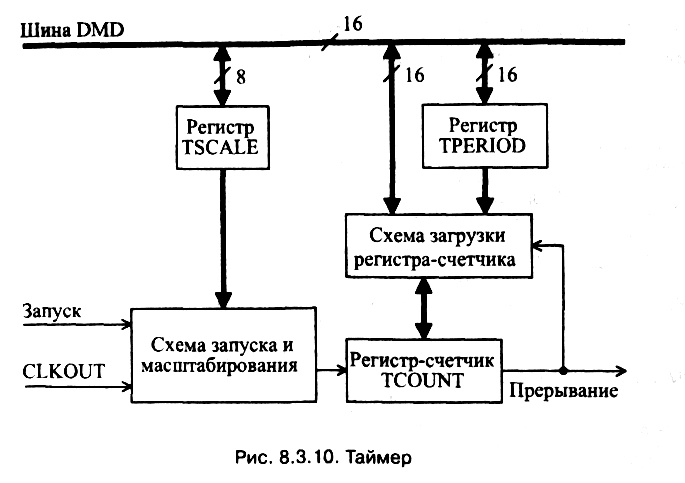 Для активизации работы SPORT0, SPORT1 необходимо установить в единичное состояние биты в позициях SR.12, SR.11 системного регистра (см. табл. 8.2.2). С помощью бита в позиции SR.10 этого же регистра можно изменять режим работы линий (выводов) SPORT1: при нулевом состоянии SR.10 линии используются по прямому назначению, при единичном состоянии SR.10 выполняют альтернативные функции (табл. 8.3.10). Передаваемые и принимаемые биты данных синхронизируются импульсами SCLK. Для синхронизации могут быть использованы внешние и внутренние синхроимпульсы. Источник синхроимпульсов задается установкой бита ISCLK в позиции CR.14 регистра управления SPORTn (табл. 8.3.11).
Для активизации работы SPORT0, SPORT1 необходимо установить в единичное состояние биты в позициях SR.12, SR.11 системного регистра (см. табл. 8.2.2). С помощью бита в позиции SR.10 этого же регистра можно изменять режим работы линий (выводов) SPORT1: при нулевом состоянии SR.10 линии используются по прямому назначению, при единичном состоянии SR.10 выполняют альтернативные функции (табл. 8.3.10). Передаваемые и принимаемые биты данных синхронизируются импульсами SCLK. Для синхронизации могут быть использованы внешние и внутренние синхроимпульсы. Источник синхроимпульсов задается установкой бита ISCLK в позиции CR.14 регистра управления SPORTn (табл. 8.3.11).

Частота внутренних синхроимпульсов определяется по формуле: Частота SCLK = 0,5 x (частота CLKOUT)/(SCLKDIV+1), где частота CLKOUT — частота импульсов тактового генератора (на внешнем выводе CLKOUT); SCLKDIV — значение 16–разрядного программно доступного регистра–делителя частоты SCLKDIV (его адрес 0x3FF5 для SPORT0 и 0x3FF1 для SPORT1). Число передаваемых бит в слове можно изменять в пределах от 3 до 16. Длина слова может быть задана с помощью четырехразрядного кода (биты в позиции CRn.0–CRn.3 регистров управления SPORTn, см. табл. 8.3.11). При этом Длина слова = SLEN + 1. Рассмотрим процессы при обмене данными с внешним устройством.
Передача
После записи данных в регистр TX сигнал TFS активизирует начало передачи. Данные из регистра TX поступают в сдвигающий регистр передатчика, а из него по фронту импульсов SCLK каждый бит, начиная с самого младшего, посылается во внешнее устройство.
После отправления самого младшего бита SPORTn генерирует сигнал прерывания передачи. Регистр TX снова становится доступным для записи новых данных.
Прием. Первым из внешнего устройства в сдвигающий регистр приемника поступает самый младший бит передаваемого слова. Последующие биты поступают синхронно с импульсами SCLK. Как только сдвигающий регистр принимает все слово, оно записывается в регистр RX, после чего SPORTn генерируется сигнал прерывания приема данных.
Кадровые сигналы
Кадровые сигналы используются для синхронизации при передаче и приеме слов. Биты RFSR = 1 в позиции CRn.13 регистра управления SPORTn (табл. 8.3.11) при приеме и TFSR=1 в позиции CRn.11 при передаче устанавливают режим работы последовательных портов с использованием кадровой синхронизации. При RFSR = 0, TFSR = 0 кадровые сигналы используются (аппаратно) только для приема/передачи первого бита. Д
альнейший обмен протекает без участия кадровых сигналов. Для кадровой синхронизации могут использоваться как внутренние, так и внешние сигналы.
Разрешение приема/передачи с использованием внутренних сигналов синхронизации производится установкой бит IRFS/ITFS (позиция CRn.8/ CRn.9) регистра управления SPORTn.
В этом режиме сигналы кадровой синхронизации поступают на выводы процессора RFS/TFS для передачи во внешние устройства. При IRFS = 0, ITFS = 0 используются внешние сигналы кадровой синхронизации, поступающие на выводы RFS, TFS из внешних устройств. Внутренний сигнал кадровой синхронизации при передаче генерируется после того, как последний бит текущего слова данных передан из регистра ТХn в сдвигающий регистр. Внутренний сигнал кадровой синхронизации при приеме контролирует прием данных. Период следования сигналов должен обеспечить синхронный прием данных, поступающих из внешнего устройства. Он устанавливается соответствующей загрузкой 16–разрядного регистра–делителя частоты RFSDIV (его адрес 0x3FF4 для SPORT0 и 0x3FF0 для SPORT1):
Число циклов между сигналами RFS =RFSDIV + 1. Для приема и передачи могут быть использованы как раздельные сигналы кадровой синхронизации, так и один общий сигнал. После сброса устанавливается режим с внешними сигналами кадровой синхронизации. Возможны два режима кадровой синхронизации:
? нормальный кадровый режим, если биты ширины сигнала кадровой синхронизации приема RFSW = 0 (позиция CRn.12) или передачи TFSW = 0 (позиция CRn.10) в регистре управления SPORTn. В этом режиме сигналы кадровой синхронизации проверяются на заднем фронте импульсов SCLK.
В случае регистрации сигнала передаваемые данные отправляются на переднем фронте следующего импульса SCLK, а принимаемые данные фиксируются на заднем фронте следующего импульса SCLK.
При непрерывном приеме или передаче данных, когда за последним битом одного слова сразу же следует первый бит следующего, сигнал кадровой синхронизации должен приходить в том же цикле, что и бит данных. После сброса устанавливается нормальный кадровый режим;
? альтернативный кадровый режим, если биты ширины сигнала кадровой синхронизации приема RFSW = 1 (позиция CRn.12) или передачи TFSW = 1 (позиция CRn.10) в регистре управления SPORTn. В этом режиме сигналы кадровой синхронизации должны приходит в том же цикле, в котором принимается/отправляется первый бит. При этом также передаваемые данные отправляются на переднем фронте следующего импульса SCLK, а принимаемые данные фиксируются на заднем фронте следующего импульса SCLK. Однако сигнал кадровой синхронизации проверяется только для первого бита. С помощью бит INVRFS/INVTFS в позиции CRn.6/CRn.7 регистра управления SPORTn можно изменять активный уровень сигналов кадровой синхронизации при приеме/передаче данных независимо друг от друга. При этом:
? низкому активному уровню соответствуют биты INVRFS = 0, INVTFS = 0;
? высокому активному уровню соответствуют биты INVRFS = 1, INVTFS = 1. Установки влияют на внутренние и внешние сигналы синхронизации. После сброса устанавливается высокий активный уровень.
Компрессия/декомпрессий, или компандинг (COMpressing/ exPANDING), позволяет путем логарифмического кодирования/ декодированиям минимизировать число посылаемых бит данных при передаче, а при приеме восстановить начальное число переданных бит.
Процессоры ADSP–21XX Поддерживают алгоритмы компандинга по А–закону и u–закону в соответствии со спецификацией CCITT G.117.
Разрешение компандинга и выбор его алгоритма осуществляется битами DATE1, DATE0 (позиция CRn.5, CRn.4) регистра управления SPORTn (табл. 8.3.11): 10 — по u–закону; 11 — А–закону.
При установке двухразрядных двоичных кодов 00 и 01 используются форматы данных, при которых все значащие биты сдвинуты к правому краю, а незначащие разряды заполнены соответственно нулями или знаковым расширением. При выборе этих кодов компандинг запрещен. При передаче сжатых данных:
? сначала передаваемые данные поступают в регистр ТХn;
? с помощью схемы компрессии/декомпрессии производится компрессия данных;
? сжатые данные вновь поступают в регистр ТХn;
? из регистра ТХn данные переписываются в сдвигающий регистр передатчика, после чего начинается передача данных во внешнее устройство. Первым передается младший бит. После этого генерируется прерывание и в регистр ТХn может быть записано следующее слово. При приеме сжатых данных:
? поступающие из внешнего устройства биты накапливаются в сдвигающем регистре приемника;
? после приема последнего бита слова, содержимое сдвигающего регистра переписывается в регистр RXn;
? с помощью схемы компрессии/декомпрессии производится декомпрессия данных;
? восстановленные в схеме компрессии/декомпрессии данные переписываются обратно в регистр RXn;
? генерируется сигнал прерывания. Так как оба порта SPORTn (n = 0, 1) обслуживаются одной схемой компрессии/ декомпрессии, при одновременном запросе на компандинг обоих портов приоритет имеет SPORT0.
Автобуферизация
В режиме автобуферизации прерывания генерируются после того, как передан или получен целый блок данных. Поэтому подпрограммы прерываний работают с целым блоком данных (а не с одним словом, как в обычном режиме), что уменьшает временные затраты при обмене данными с внешними устройствами.
Режим автобуферизации при приеме/передаче активизируется битами RBUFn/TBUFn в позициях САn.0/САn.1 регистра управления автобуферизацией SPORTn (табл. 8.3.12). После сброса процессора режим автобуферизации деактивизиру–ется.
Трехразрядный двоичный код позволяет выбрать номер (0–7) индексного регистра I, используемого при приеме/передаче (биты RIREGn.0–RIREGn.2 в позициях САn.4–САn.6/биты TIREGn.0–TIREGn.2 в позициях CAn.9–CAn.11).
Двухразрядный код позволяет выбрать номер регистра модификации М, используемого при приеме/передаче (биты RMREGn.0, RMREGn.1 в позициях САn.2–САn.З/биты TIREGn.0,TIREGn.2 в позициях САn.7–САn.8). Номера регистров I и М могут быть любыми: 0–3 для DAG1 и 4–7 для DAG2, т. е. регистры I и М должны принадлежать одному и тому же генератору адресов данных. Поэтому старшие разряды трехразрядного кода для регистров I и М совпадают и для выбора номера регистра М используется двухразрядный код. 
 В режиме автобуферизации с помощью генераторов адресов данных DAG используется изложенный выше принцип адресации кольцевых буферов. Многоканальный режим. Многоканальный режим может быть реализован только в порте SPORT0. В этом режиме каждое последующее слово передается по следующему каналу. Порт SPORT0 поддерживает 24– и 32–канальные режимы работы. При этом имеется возможность для разрешения и запрета любого канала. Многоканальный режим устанавливается битом МСЕ = 1 в позиции CR0.15 регистра управления SPORT0 (табл. 8.3.11). В этом режиме биты в позициях CR0.9–CR0.13 задействованы для обслуживания многоканального режима:
В режиме автобуферизации с помощью генераторов адресов данных DAG используется изложенный выше принцип адресации кольцевых буферов. Многоканальный режим. Многоканальный режим может быть реализован только в порте SPORT0. В этом режиме каждое последующее слово передается по следующему каналу. Порт SPORT0 поддерживает 24– и 32–канальные режимы работы. При этом имеется возможность для разрешения и запрета любого канала. Многоканальный режим устанавливается битом МСЕ = 1 в позиции CR0.15 регистра управления SPORT0 (табл. 8.3.11). В этом режиме биты в позициях CR0.9–CR0.13 задействованы для обслуживания многоканального режима:
? при значении бита MCL = 0 (позиция CR0.9) устанавливается 24–канальный режим, при MCL = 1 — 32–канальный;
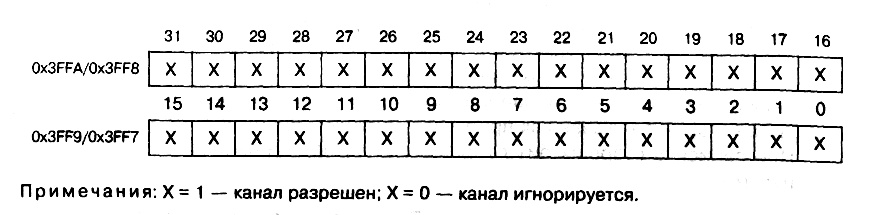
? четырехразрядный код MFD3…MFD0 (позиции CR0.10–CR0.13) задает задержку сигнала кадровой синхронизации, т. е. число циклов SCLK между сигналом кадровой синхронизации и первым битом данных. С помощью 32–разрядных регистров разрешения многоканального приема/ передачи SPORT0 можно разрешить или запретить любой из 24 или 32 каналов. Для обращения к регистрам используются два адреса: 0x3FF9, 0x3FFA — при приеме; 0x3FF7, 0x3FF8 — при передаче. Для запрещенных каналов:
? принимаемые слова игнорируются. Для этих слов прерывания не генерируются, автобуферизация запрещена и они не заносятся в регистр RX0;
? подлежащие передаче слова не передаются. Для этих слов прерывания не генерируются, автобуферизация запрещена. Выход передачи данных DT находится в высокоомном состоянии. В многоканальном режиме остаются в силе многие опции, устанавливаемые битами регистра управления SPORT0 и управления автобуферизацией (табл. 8.3.11 и 8.3.12).
Например: SLEN — длина слова; DTYPE — компандинг и формат данных; IRFS — внутренние/внешние сигналы кадровой синхронизации; INVRFS — активный уровень кадровых сигналов и др.
Устройство обмена между шинами PMD–DMD. Это устройство (рис. 8.3.9) предназначено для обмена данными между шинами данных памяти программ (PMD) и данных памяти данных (DMD) в обоих направлениях.
Как видно из рис. 8.3.9, возможен обмен данными между 16 старшими разрядами 24–разрядной шины PMD и 16–разрядной шиной DMD, который реализуется с помощью двух буферов с тремя состояниями. Для обмена младшими байтами данных используется восьмиразрядный регистр РХ. В процессорах ADSP–21 возможны следующие способы доступа к регистру РХ:
? регистр РХ автоматически загружается с шины PMD при считывании данных с этой шины в любой регистр. Например: при выполнении команды AX0 = PM(I4,M4) старшие 16 бит 24–битного слова памяти программ считываются в регистр АХ, а младшие 8 бит автоматически загружаются в РХ;
? из регистра РХ автоматически считываются младшие 8 бит на шину РМD при записи данных в память программ. Например: при выполнении команды PM(I4,M4) = AX0 записываются в память программ 16 бит, считанных из регистра АХ, и 8 бит, считанных из регистра РХ;
? регистр РХ доступен для записи/чтения при использовании команд пересылки, в которых он указан как приемник/источник. Например, РХ = АХ0; АХ0 = РХ. При записи 8 старших бит отбрасываются, при считывании — заполняются нулями.
Таймер
Назначение и состав
Таймер предназначен для генерирования периодических прерываний через заданное число процессорных циклов.
В состав таймера входят (рис. 8.3.10):
? 16–разрядный регистр–счетчик TCOUNT с декрементацией содержимого каждый процессорный цикл;
? 16–разрядный регистр TPERIOD, содержимое которого определяет период генерирования прерываний;
? 8–разрядный регистр TSCALE, содержащий коэффициент масштабирования, который на единицу меньше числа процессорных циклов между декрементами счетчика.
Принцип работы
Включение таймера осуществляется установкой бита TIMER (позиция MSTAT.5) регистра режима и статуса процессора (табл. 8.3.9). Через каждый процессорный цикл содержимое регистра–счетчика TCOUNT уменьшается на единицу. Когда регистр–счетчик становится пустым, таймер генерирует прерывание и в него загружается содержимое регистра TPERIOD. Число циклов между прерываниями определяется по формулам:
? для первого прерывания число циклов = (TCOUNT + 1 ) х (TSCALE + 1 );
? для последующих прерываний число циклов = (TPERIOD + 1) х (TSCALE +1). Изменения содержимого регистров TCOUNT и TSCALE активизируются немедленно, изменения содержимого регистра TPERIOD — только после перезагрузки регистра TCOUNT содержимым TSCALE. Интерфейс с ведущим процессором. Назначение и состав. Интерфейс с ведущим процессором (Host Interface Processor — HIP) представляет собой параллельный порт ввода–вывода, обеспечивающий обмен данными между внешним ведущим и ведомым процессорами. Его можно также представить:
? для ведущего процессора как область памяти или регистров ведомого процессора, доступную для чтения и записи. Эта область задается набором 8– или 16–разрядных адресов;
? для ведомого процессора набором из восьми регистров, адресуемых по адресам памяти данных. Ведущий процессор может быть подключен к HIP нескольких ведомых процессоров. Обмен данными между ведомыми процессорами происходит через ведущий процессор. 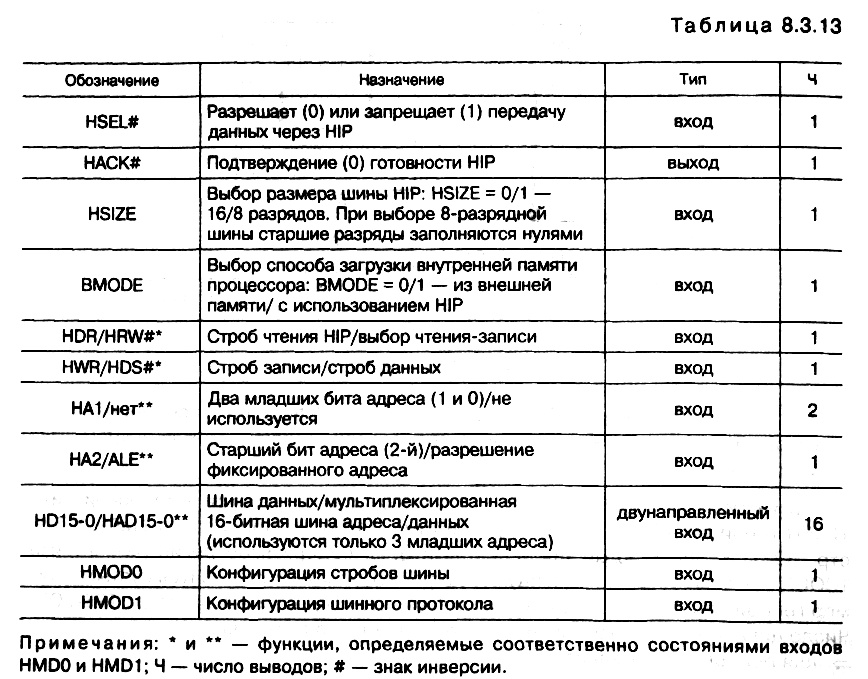 Интерфейс HIP имеет 27 выводов (табл. 8.3.13), из которых 11 служат для управления, а 16 являются входами/выходами для данных. В состав интерфейса HIP входят (рис. 8.3.11):
? блок управления интерфейсом (HCI), обеспечивающий управление чтением/ записью регистров HIP и загрузкой внутренней памяти программ процессора;
Интерфейс HIP имеет 27 выводов (табл. 8.3.13), из которых 11 служат для управления, а 16 являются входами/выходами для данных. В состав интерфейса HIP входят (рис. 8.3.11):
? блок управления интерфейсом (HCI), обеспечивающий управление чтением/ записью регистров HIP и загрузкой внутренней памяти программ процессора;
? 16–разрядные регистры данных HDR0–HDR5, доступные по адресам памяти данных 0xFE0–0xFE5 как ведущему, так и ведомым процессорам. При чтении и записи в регистры ведущим процессором генерируется маскируемое прерывание чтения и записи HIP;
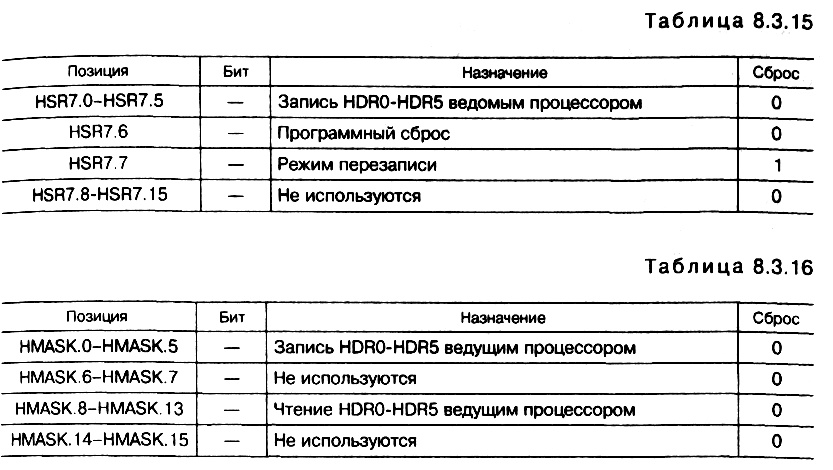
? статусные регистры HSR6 (табл. 8.3.14) и HSR7 (табл. 8.3.15), в которые записывается состояние HDR–регистров. Младшие шесть бит регистра HSR7 копируются из регистра HSR6, чтобы 8–битные ведущие процессоры могли считать оба статуса;
? регистр маскирования прерываний HMASK (табл. 8.3.16). 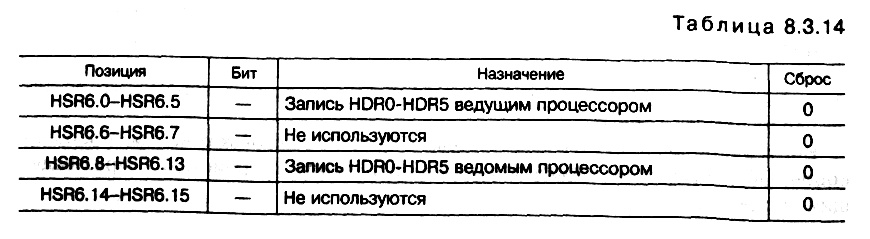
Работа с HIP
Ведущий процессор помещает данные в один из регистров HDR для последующего их считывания ведомым процессором (и наоборот). Для ведущих процессоров (с подтверждением) сигнал подтверждения HACK устанавливается ведомым процессором в том же цикле, что и сигнал доступа HSEL. В режиме перезаписи, который устанавливается битом HSR7.7 статусного регистра HSR7, неустановкой сигнала подтверждения можно отложить доступ к HIP.
Ведущий процессор, требующий подтверждения, может оказаться в состоянии «бесконечного ожидания». Инициализация регистров данных HDR не предусмотрена.
Поэтому ведущий процессор может записать данные в регистр HDR до сброса, а ведомый процессор считать эти данные из регистра после сброса.
Метод опроса
Наличие в интерфейсе HIP статусных регистров HSR позволяет путем их опроса определить состояние регистров данных HDR. Следовательно, опрос можно использовать как способ передачи данных между ведущим и ведомым процессорами. При записи данных в один из регистров HDR ведущим процессором в младшем байте статусного регистра HSR6 в соответствующей позиции устанавливается бит.
Аналогично при записи данных в один из регистров HDR ведомым процессором в старшем байте статусного регистра HSR6 (или в младшем байте статусного регистра HSR7) в соответствующей позиции устанавливается бит.
Установленные биты сохраняются до их прочтения ведомым или ведущим процессором.
Процессы в ведущем и ведомом процессорах протекают асинхронно и, если не принять никаких мер, содержимое статусных регистров HSR может изменяться во время считывания из них информации, что приведет к непредсказуемым результатам. Однако HIP располагает аппаратными средствами, гарантирующими постоянство содержимого HSR при чтении.
Получение достоверных результатов при чтении статусных регистров HSR ведущим процессором базируется на псевдосинхроимпульсах HCLK = ?(?HSEL ^ ?HRD ^ ?HWR). При HCLK = 1 ведущий процессор имеет доступ к HIP.
Аппаратные средства позволяют обновлять статус при его изменении. Как показано на рис. 8.3.12, независимо от того, когда произошло изменение статуса при HCLK = 0 или HCLK = 1, бит статуса ведущего процессора в статусных регистрах HSR обновляется (переписывается) на срезе следующего импульса HCLK.
Поэтому чтение регистров HSR с задержкой в один процессорный цикл даст достоверное значение статусного бита. Для ведомого процессора обновление статуса всегда происходит по переднему фронту импульса CLKOUT, при этом один импульс пропускается.
Работа с прерываниями
При этом способе передачи данных после записи данных ведущим процессором в один из регистров HDR интерфейсом HIP автоматически генерируется внутреннее прерывание. В процессе обслуживания этого прерывания происходит считывание данных ведомым процессором из HDR. Для передачи данных ведущему процессору ведомый процессор записывает данные в один из регистров HDR, после чего устанавливает выходной флаг, который информирует ведущий процессор о поступлении новых данных.
Если ведомый процессор передает данные через один регистр HDR, ведущий процессор может непосредственно считать этот регистр по получению прерывания. Если же при передаче данных используется несколько регистров HDR, ведущий процессор сначала определяет, в какой из регистров произведена запись. Для этого используется соответствующий HSR–регистр.
Режим перезаписи HDR –регистров
Как правило, ведомый процессор успевает считывать данные из регистра HDR, посылаемые ведущим процессором. В противном случае могут возникать задержки при обработке прерываний записи ведущего процессора. Если ведущий процессор использует сигнал подтверждения HACK, выставляемый ведомым процессором, можно задержать передачу последующих данных ведущим процессором до тех пор, пока ведомым процессором не будут обработаны текущие данные.
При очищенном бите перезаписи (позиция HSR7.7) сигнал HACK не устанавливается до тех пор, пока ведомый процессор не считает старые данные. Ведущий процессор не может записать новые данные в регистр HDR и должен ожидать установки сигнала подтверждения HACK.
Однако наличие синхронизационной задержки между фактическим изменением состояния и отражением его в статусном регистре позволяет ведущему процессору сделать повторную запись в HDR–регистр даже при очищенном бите режима перезаписи. При установленном бите перезаписи в статусном регистре HSR7 предыдущее содержимое HDR–регистра переписывается и сразу же устанавливается сигнал подтверждения HACK для записи ведущим процессором новых данных.
Ведомый процессор не должен считывать содержимое HDR–регистра до записи новых данных. Для ведущих процессоров, не использующих сигнал подтверждения HACK, бит режима перезаписи HDR–регистров должен быть установлен, поскольку в этом случае не существует возможности предотвратить перезапись.
Прерывания от HIP
После записи ведущим процессором данных в HDR–регистр интерфейс HIP генерирует сигнал прерывания записи. После того, как ведущий процессор прочитал содержимое соответствующего HDR–регистра и ведомый процессор может производить в него запись, интерфейс HIP генерирует сигнал прерывания чтения. Сигналы прерывания чтения и записи не очищаются после обработки прерывания. При чтении/записи HDR–регистра происходит очистка сигнала прерывания записи/чтения.
Логическая комбинация всех запросов прерываний чтения и записи генерирует прерывание от HIP. Запрос прерывания сохраняется до тех пор, пока все сигналы прерывания HIP не будут очищены чтением или записью соответствующих HDR–регистров.
При чтении ведомым процессором HDR–регистра, в который может быть записана информация ведущим процессором, прерывание HIP может не генерироваться. Если ведущий процессор никогда не читает HDR–регистр, при каждой записи в него данных ведущим процессором интерфейс HIP генерирует прерывание. Информация из статусных регистров может быть считана во время обработки прерывания.
Прерывания от HIP могут быть программно сгенерированы и очищены. Регистр маскирования HMASK (табл. 8.3.16) позволяет запретить прерывания чтения и записи любого из HDR–регистров путем сброса (в нулевое состояние) соответствующего бита.
Начальная загрузка внутренней памяти с использованием HIP
Этот способ загрузки реализуется при BMODE = 1 (табл. 8.3.13). Сигнал BMS = 0 (см. рис. 8.2.3) активизирует загрузочную память и служит индикатором того, что происходит начальная загрузка. Начальная загрузка внутренней памяти программ процессора выполняется по следующему алгоритму:
? шаг 1. После сброса ведущий процессор записывает в регистр данных HDR3 длину загрузочной последовательности и переходит в режим ожидания (минимум два процессорных цикла);
? шаг 2. По самому старшему адресу внутренней памяти загружается первая команда программы. Для этого ведущий процессор предварительно записывает команду в регистры НDR0, НDR2, НDR1. Сначала записывается старший байт в регистр НDR0, затем младший байт — в НDR2 и, наконец, средний байт — в НDR1. Ведомый процессор сначала читает длину загрузочной последовательности, затем загружает байты во внутреннюю память, начиная с самого старшего адреса;
? шаг 3. Для записи следующей команды адрес уменьшается на единицу и шаг 2 повторяется до тех пор, пока не будет загружена последняя команда. Число загружаемых команд должно быть кратным восьми. При этом длина загрузочной последовательности = (число 24–битных команд/8) – 1. Если ведущий процессор работает быстрее ведомого, вводятся циклы ожидания или пустые команды NOP.

Такие кошечки встречаются с порядочными и приятными мужчинами, проверенные путаны Барабинск по вызову, доставят вам настоящее наслаждение. Поверьте, только проститутки способны подарить вам лучший секс в вашей жизни. Милые проверенные путаны Барабинск по вызову, страстные и желанные, они такие интересные и чуткие, что ты не устоишь перед ними. Не отказывай себе в удовольствии.