Первая часть данной статьи.
Первая часть данной статьи.
Организация таблицы символьных имен в ассемблере.
В этой таблице содержится информация о символах и их значениях, собранная ассемблером во время первого прохода. К таблице символьных имен ассемблер обращается во втором проходе. Рассмотрим способы организации таблицы символьных имен. Представим таблицу как ассоциативную память, хранящую набор пар: символьное имя — значение. Ассоциативная память по имени должна выдавать его значение. Вместо имени и значения могут фигурировать указатель на имя и указатель на значение.
Последовательное ассемблирование.
Таблица символьных имен представляется как результат первого прохода в виде массива пар имя — значение. Поиск требуемого символа осуществляется последовательным просмотром таблицы до тех пор, пока не будет определено соответствие. Такой способ довольно легко программируется, но медленно работает.
Сортировка по именам.
Имена предварительно сортируется по алфавиту. Для поиска имен используется алгоритм двоичного отсечения, по которому требуемое имя сравнивается с именем среднего элемента таблицы. Если нужный символ расположен по алфавиту ближе среднего элемента, то он находится в первой половине таблицы, а если дальше, то во второй половине таблицы. Если нужное имя совпадаете именем среднего элемента, то поиск завершается.
Алгоритм двоичного отсечения работает быстрее, чем последовательный просмотр таблицы, однако элементы таблицы необходимо располагать в алфавитном порядке.

Кэш–кодирование.
При этом способе на основании исходной таблицы строится кэш–функция, которая отображает имена в целые числа в промежутке от О до k–1 (рис. 5.2.1, а). Кэш–функцией может быть, например, функция перемножения всех разрядов имени, представленного кодом ASCII, или любая другая функция, которая дает равномерное распределение значений. После этого создается кэш–таблица, которая содержит к строк (слотов). В каждой строке располагаются (например, в алфавитном порядке) имена, имеющие одинаковые значения кэш–функции (рис. 5.2.1, б), или номер слота. Если в кэш–таблице содержится п символьных имен, то среднее количество имен в каждом слоте составляет n/k. При n = k для нахождения нужного символьного имени в среднем потребуется всего один поиск. Путем изменения к можно варьировать размер таблицы (число слотов) и скорость поиска. Связывание и загрузка. Программу можно представить как совокупность процедур (подпрограмм). Ассемблер поочередно транслируют одну процедуру за другой, создавая объектные модули и размещая их в памяти. Для получения исполняемого двоичного кода должны быть найдены и связаны все оттранслированные процедуры.
Функции связывания и загрузки выполняют специальные программы, называемые компоновщиками, связывающими загрузчиками, редакторами связей или линкерами.
 Таким образом, для полной готовности к исполнению исходной программы требуется два шага (рис. 5.2.2):
Таким образом, для полной готовности к исполнению исходной программы требуется два шага (рис. 5.2.2):
? трансляция, реализуемая компилятором или ассемблером для каждой исходной процедуры с целью получения объектного модуля. При трансляции осуществляется переход с исходного языка на выходной язык, имеющий разные команды и запись;
? связывание объектных модулей, выполняемое компоновщиком для получения исполняемого двоичного кода. Отдельная трансляция процедур вызвана возможными ошибками или необходимостью изменения процедур. В этих случаях понадобится заново связать все объектные модули. Так как связывание происходит гораздо быстрее, чем трансляция, то выполнение этих двух шагов (трансляции и связывания) сэкономит время при доработке программы. Это особенно важно для программ, которые содержат сотни или тысячи модулей. В операционных системах MS–DOS, Windows и NT объектные модули имеют расширение «.obj», а исполняемые двоичные программы — расширение «.ехе». В системе UNIX объектные модули имеют расширение «.о», а исполняемые двоичные программы не имеют расширения.
Функции компоновщика.
Перед началом первого прохода ассемблирования счетчик адреса команды устанавливается на 0. Этот шаг эквивалентен предположению, что объектный модуль во время выполнения будет находиться в ячейке с адресом 0.
Цель компоновки — создать точное отображение виртуального адресного пространства исполняемой программы внутри компоновщика и разместить все объектные модули по соответствующим адресам.
 Рассмотрим особенности компоновки четырех объектных модулей (рис. 5.2.3, а), полагая при этом, что каждый из них находится в ячейке с адресом 0 и начинается с команды перехода BRANCH к команде MOVE в том же модуле. Перед запуском программы компоновщик помещает объектные модули в основную память, формируя отображение исполняемого двоичного кода. Обычно небольшой раздел памяти, начинающийся с нулевого адреса, используется для векторов прерывания, взаимодействия с операционной системой и других целей.
Рассмотрим особенности компоновки четырех объектных модулей (рис. 5.2.3, а), полагая при этом, что каждый из них находится в ячейке с адресом 0 и начинается с команды перехода BRANCH к команде MOVE в том же модуле. Перед запуском программы компоновщик помещает объектные модули в основную память, формируя отображение исполняемого двоичного кода. Обычно небольшой раздел памяти, начинающийся с нулевого адреса, используется для векторов прерывания, взаимодействия с операционной системой и других целей.
Поэтому, как показано на рис. 5.2.3, б, программы начинаются не с нулевого адреса, а с адреса 100. Поскольку каждый объектный модуль на рис. 5.2.3, а занимает отдельное адресное пространство, возникает проблема перераспределения памяти. Все команды обращения к памяти не будут выполнены по причине некорректной адресации. Например, команда вызова объектного модуля B (рис. 5.2.3, б), указанная в ячейке с адресом 300 объектного модуля А (рис. 5.2.3, а), не выполнится по двум причинам:
? команда CALL B находится в ячейке с другим адресом (300, а не 200); ? поскольку каждая процедура транслируется отдельно, ассемблер не может определить, какой адрес вставлять в команду CALL В. Адрес объектного модуля В не известен до связывания. Такая проблема называется проблемой внешней ссылки. Обе причины устраняются с помощью компоновщика, который сливает отдельные адресные пространства объектных модулей в единое линейное адресное пространство, для чего:
? строит таблицу объектных модулей и их длин;
? на основе этой таблицы приписывает начальные адреса каждому объектному модулю;
? находит все команды, которые обращаются к памяти, и прибавляет к каждой из них константу перемещения, которая равна начальному адресу этого модуля (в рассматриваемом случае 100);
? находит все команды, которые обращаются к процедурам, и вставляет в них адрес этих процедур. 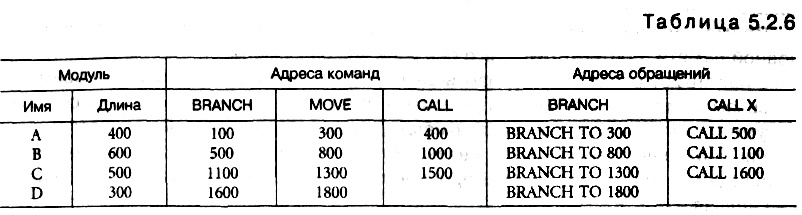 Ниже приведена таблица объектных модулей (табл. 5.2.6), построенная на первом шаге. В ней дается имя, длина и начальный адрес каждого модуля. Адресное пространство после выполнения компоновщиком всех шагов показано в табл. 5.2.6 и на рис. 5.2.3, в. Структура объектного модуля. Объектные модули состоят из следующих частей:
Ниже приведена таблица объектных модулей (табл. 5.2.6), построенная на первом шаге. В ней дается имя, длина и начальный адрес каждого модуля. Адресное пространство после выполнения компоновщиком всех шагов показано в табл. 5.2.6 и на рис. 5.2.3, в. Структура объектного модуля. Объектные модули состоят из следующих частей:
? имя модуля, некоторая дополнительная информация (например, длины различных частей модуля, дата ассемблирования);
? список определенных в модуле символов (символьных имен) вместе с их значениями. К этим символам могут обращаться другие модули. Программист на языке ассемблера с помощью директивы PUBLIC указывает, какие символьные имена считаются точками входа;
? список используемых символьных имен, которые определены в других модулях. В списке также указываются символьные имена, используемые теми или иными машинными командами. Это позволяет компоновщику вставить правильные адреса в команды, которые используют внешние имена. Благодаря этому процедура может вызывать другие независимо транслируемые процедуры, объявив (с помощью директивы EXTERN) имена вызываемых процедур внешними. В некоторых случаях точки входа и внешние ссылки объединены в одной таблице;
? машинные команды и константы;
? словарь перемещений. К командам, которые содержат адреса памяти, должна прибавляться константа перемещения (см. рис. 5.2.3). Компоновщик сам не может определить, какие слова содержат машинные команды, а какие — константы. Поэтому в этой таблице содержится информация о том, какие адреса нужно переместить. Это может быть битовая таблица, где на каждый бит приходится потенциально перемещаемый адрес, либо явный список адресов, которые нужно переместить;
? конец модуля, адрес начала выполнения, а также контрольная сумма для определения ошибок, сделанных во время чтения модуля. Отметим, что машинные команды и константы единственная часть объектного модуля, которая будет загружаться в память для выполнения. Остальные части используются и отбрасываются компоновщиком до начала выполнения программы. Большинство компоновщиков используют два прохода:
? сначала считываются все объектные модули и строится таблица имен и длин модулей, а также таблица символов, которая состоит из всех точек входа и внешних ссылок;
? затем модули еще раз считываются, перемещаются в памяти и связываются. О перемещении программ. Проблема перемещения связанных и находящихся в памяти программ обусловлена тем, что после их перемещения хранящиеся в таблицах адреса становятся ошибочными. Для принятия решения о перемещении программ необходимо знать момент времени финального связывания символических имен с абсолютными адресами физической памяти.
Временем принятия решения называется момент определения адреса в основной памяти, соответствующего символическому имени. Существуют различные варианты для времени принятия решения относительно связывания: когда пишется программа, когда программа транслируется, компонуется, загружается или когда команда, содержащая адрес, выполняется. Рассмотренный выше метод связывает символические имена с абсолютными физическими адресами. По этой причине перемещать программы после связывания нельзя.
При связывании можно выделить два этапа:
? первый этап, на котором символические имена связываются с виртуальными адресами. Когда компоновщик связывает отдельные адресные пространства объектных модулей в единое линейное адресное пространство, он фактически создает виртуальное адресное пространство;
? второй этап, когда виртуальные адреса связываются с физическими адресами. Только после второй операции процесс связывания можно считать завершенным. Необходимым условием перемещения программы является наличие механизма, позволяющего изменять отображение виртуальных адресов на адреса основной физической памяти (многократно выполнять второй этап). К таким механизмам относятся:
? разбиение на страницы. Адресное пространство, изображенное на рис. 5.2.3, в, содержит виртуальные адреса, которые уже определены и соответствуют символическим именам А, В, С и D. Их физические адреса будут зависеть от содержания таблицы страниц. Поэтому для перемещения программы в основной памяти достаточно изменить только ее таблицу страниц, но не саму программу;
? использование регистра перемещения. Этот регистр указывает на физический адрес начала текущей программы, загружаемый операционной системой перед перемещением программы. С помощью аппаратных средств содержимое регистра перемещения прибавляется ко всем адресам памяти, прежде чем они загружаются в память. Процесс перемещения является «прозрачным» для каждой пользовательской программы. Особенность механизма: в отличие от разбиения на страницы должна перемещаться вся программа целиком. Если имеются отдельные регистры (или сегменты памяти как, например, в процессорах Intel) для перемещения кода и перемещения данных, то в этом случае программу нужно перемещать как два компонента;
? механизм обращения к памяти относительно счетчика команд. При использовании этого механизма при перемещении программы в основной памяти обновляется только счетчик команд. Программа, все обращения к памяти которой связаны со счетчиком команд (либо абсолютны как, например, обращения к регистрам устройств ввода–вывода в абсолютных адресах), называется позиционно–независимой программой. Такую программу можно поместить в любом месте виртуального адресного пространства без настройки адресов. Динамическое связывание.
Рассмотренный выше способ связывания имеет одну особенность: связь со всеми процедурами, нужными программе, устанавливается до начала работы программы. Более рациональный способ связывания отдельно скомпилированных процедур, называемый динамическим связыванием, состоит в установлении связи с каждой процедурой во время первого вызова. Впервые он был применен в системе MULTICS. 
Динамическое связывание в системе MULTICS. За каждой программой закреплен сегмент связывания, содержащий блок информации для каждой процедуры (рис. 5.2.4).
Информация включает:
? слово «Косвенный адрес», зарезервированное для виртуального адреса процедуры;
? имя процедуры (EARTH, FIRE и др.), которое сохраняется в виде цепочки символов. При динамическом связывании вызовы процедур во входном языке транслируются в команды, которые с помощью косвенной адресации обращаются к слову «Косвенный адрес» соответствующего блока (рис. 5.2.4). Компилятор заполняет это слово либо недействительным адресом, либо специальным набором бит, который вызывает системное прерывание (типа ловушки). После этого:
? компоновщик находит имя процедуры (например, EARTH) и приступает к поиску пользовательской директории для скомпилированной процедуры с таким именем;
? найденной процедуре приписывается виртуальный адрес «Адрес EARTH» (обычно в ее собственном сегменте), который записывается поверх недействительного адреса, как показано на рис. 5.2.4;
? затем команда, которая вызвала ошибку, выполняется заново. Это позволяет программе продолжать работу с того места, где она находилась до системного прерывания. Все последующие обращения к процедуре EARTH будут выполняться без ошибок, поскольку в сегменте связывания вместо слова «Косвенный адрес» теперь указан действительный виртуальный адрес «Адрес EARTH». Таким образом, компоновщик задействован только тогда, когда некоторая процедура вызывается впервые. После этого вызывать компоновщик не требуется.
Динамическое связывание в системе Windows.
Для связывания используются динамически подключаемые библиотеки (Dynamic Link Library — DLL), которые содержат процедуры и (или) данные. Библиотеки оформляются в виде файлов с расширениями «.dll», «.drv» (для библиотек драйверов — driver libraries) и «.fon» (для библиотек шрифтов — font libraries). Они позволяют свои процедуры и данные разделять между несколькими программами (процессами). Поэтому самой распространенной формой DLL является библиотека, состоящая из набора загружаемых в память процедур, к которым имеют доступ несколько программ одновременно. В качестве примера на рис. 5.2.5 показаны четыре процесса, которые разделяют файл DLL, содержащий процедуры А, В, С и D. Программы 1 и 2 использует процедуру А; программа 3 — процедуру D, программа 4 — процедуру В. 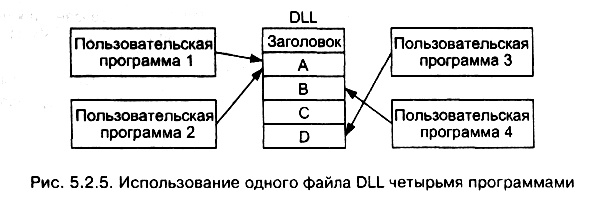 Файл DLL строится компоновщиком из набора входных файлов. Принцип построения подобен построению исполняемого двоичного кода. Отличие проявляется в том, что при построении файла DLL компоновщику передается специальный флаг для сообщения о создании DLL. Файлы DLL обычно конструируются из набора библиотечных процедур, которые могут понадобиться нескольким процессорам. Типичными примерами файлов DLL являются процедуры сопряжения с библиотекой системных вызовов Windows и большими графическими библиотеками. Использование файлов DDL позволяет:
Файл DLL строится компоновщиком из набора входных файлов. Принцип построения подобен построению исполняемого двоичного кода. Отличие проявляется в том, что при построении файла DLL компоновщику передается специальный флаг для сообщения о создании DLL. Файлы DLL обычно конструируются из набора библиотечных процедур, которые могут понадобиться нескольким процессорам. Типичными примерами файлов DLL являются процедуры сопряжения с библиотекой системных вызовов Windows и большими графическими библиотеками. Использование файлов DDL позволяет:
? сэкономить пространство в памяти и на диске. Например, если какая–то библиотека была связана с каждой использующей ее программой, то эта библиотека будет появляться во многих исполняемых двоичных программах в памяти и на диске. Если же использовать файлы DLL, то каждая библиотека будет появляться один раз на диске и один раз в памяти;
?упростить обновление библиотечных процедур и, кроме того, осуществить обновление, даже после того как программы, использующие их, были скомпилированы и связаны;
? исправлять обнаруженные ошибки путем распространения новых файлов DLL (например, по Интернету). При этом не требуется производить никаких изменений в основных бинарных программах. Основное различие между файлом DLL и исполняемой двоичной программой состоит в том, что файл DLL:
? не может запускаться и работать сам по себе, поскольку у него нет ведущей программы;
? содержит другую информацию в заголовке;
? имеет несколько дополнительных процедур, не связанных с процедурами в библиотеке, например, процедуры для выделения памяти и управления другими ресурсами, которые необходимы файлу DLL. Программа может установить связь с файлом DLL двумя способами: с помощью неявного связывания и с помощью явного связывания. При неявном связывании пользовательская программа статически связывается со специальным файлом, называемым библиотекой импорта.
Эта библиотека создается обслуживающей программой, или утилитой, путем извлечения определенной информации из файла DLL. Библиотека импорта через связующий элемент позволяет пользовательской программе получать доступ к файлу DLL, при этом она может быть связана с несколькими библиотеками импорта. Система Windows при неявном связывании контролирует загружаемую для выполнения программу. Система выявляет, какие файлы DLL будет использовать программа, и все ли требуемые файлы уже находятся в памяти. Отсутствующие файлы немедленно загружаются в память.
Затем производятся соответствующие изменения в структурах данных библиотек импорта для того, чтобы можно было определить местоположение вызываемых процедур. Эти изменения отображаются в виртуальное адресное пространство программы, после чего пользовательская программа может вызывать процедуры в файлах DLL, как будто они статически связаны с ней, и ее запускают.
При явном связывании не требуются библиотеки импорта и не нужно загружать файлы DLL одновременно с пользовательской программой. Вместо этого пользовательская программа:
? делает явный вызов прямо во время работы, чтобы установить связь с файлом DLL;
? затем совершает дополнительные вызовы, чтобы получить адреса процедур, которые ей требуются;
? после этого программа совершает финальный вызов, чтобы разорвать связь с файлом DLL;
? когда последний процесс разрывает связь с файлом DLL, — этот файл может быть удален из памяти. Следует отметить, что при динамическом связывании процедура в файле DLL работает в потоке вызывающей программы и для своих локальных переменных использует стек вызывающей программы. Существенным отличием работы процедуры при динамическом связывании (от статического) является способ установления связи.

Посмотри какие прелестницы встречаются с достойным состоятельным мужчиной, реальные путаны в Саратове, очень люблю секс и всякие безумства. Проститутки могут вам предложить самую сказочную ночь в вашей жизни. Милые реальные путаны в Саратове, сладкие и ухоженные, они такие активные и чуткие, что возбуждение неизбежно. Не упусти свой шанс.