Коротко: основной расход электроэнергии в экосистеме ИИ — это дата-центры (тренировка и особенно инференс моделей), плюс охлаждение и сетевая инфраструктура. По оценкам профильных агентств и исследователей, мировой спрос на электричество для дата-центров продолжит быстро расти к 2030 году, а доля нагрузок, связанных с ИИ, увеличивается быстрее остальных. Одновременно растут водные затраты на охлаждение.
Прозрачности по метрикам мало, а средние цифры по отрасли легко вводят в заблуждение. Ниже — системный разбор и практические шаги для снижения энергозатрат без потери качества сервиса.

- Что считать «ресурсами для ИИ»
- Текущий масштаб и динамика
- Где именно тратится энергия
- Региональная концентрация нагрузки
- Вода и охлаждение: скрытая цена
- Что будет дальше до 2030 года
- Методологические риски и почему цифры так расходятся
- Практические шаги для компаний
- Что делать редакциям, продуктам и ИИ-стартапам уже сегодня
- Вывод
- Источники
Что считать «ресурсами для ИИ»
- Тренировка (training): неделями и днями работают GPU-кластеры, формируя веса моделей.
- Инференс (inference): ежедневные ответы моделей пользователям/сервисам; по мере масштабирования трафика именно инференс становится главным источником операционных затрат энергии.
- Инфраструктура дата-центров: электропитание, ИБП, охлаждение (воздух/жидкость), маршрутизаторы и т. п.
- Хранилища и данные: подготовка датасетов, хранение, выгрузки, кэширование.
- Сети: L2/L3 внутри ЦОД, магистральные каналы, CDN — особенно при мультимодальном контенте.
- Край (edge): локальные ускорители, on-prem кластера, устройства пользователей (редко критично, но в сумме заметно).
Текущий масштаб и динамика
Глобальное потребление электроэнергии дата-центрами, включая ИИ-нагрузки, устойчиво растёт и к концу десятилетия может примерно удвоиться относительно середины 2020-х. Профильные модели прогнозов указывают на то, что именно ИИ — ключевой драйвер этого роста.
Разброс оценок велик из-за недостатка раскрытий со стороны компаний и различий в методиках. Важно: абсолютные цифры по отрасли менее полезны, чем понимание структуры вашей нагрузки (сколько токенов/запросов, какие модели/квантизация, каков PUE/WUE вашего провайдера и т. д.).
Где именно тратится энергия
- Инференс сегодня даёт основную долю энергопотребления для массовых продуктов на ИИ. Причины: постоянный поток запросов, «длинные хвосты» токенов, мультимодальность, контекстные окна и RAG.
- Тренировка — «редкая, но тяжёлая» нагрузка. Единичные прогоны крупных моделей могут съедать сопоставимые с малыми городами объёмы энергии, но в годовом профиле компании это обычно всплески.
- Охлаждение и потери (PUE) — всё, что не доходит до чипа: вентиляторы/насосы, трансформация напряжения, неидеальная утилизация стоек.
- Сеть и хранение — заметно при широком использовании RAG, стриминга ответов, аудио/видео-модальностей.
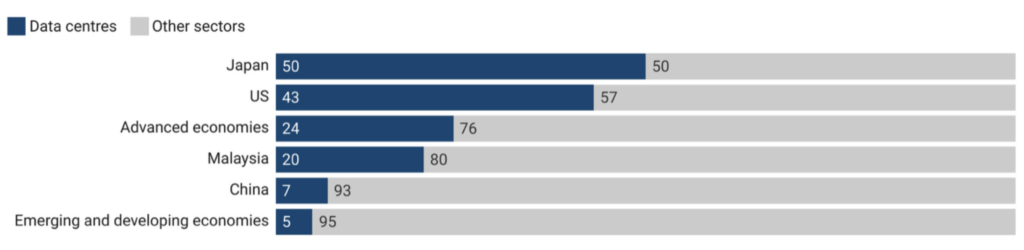
Региональная концентрация нагрузки
Энергопотребление ЦОД распределено неравномерно. Отдельные страны и даже агломерации (например, технологические кластеры в США и Ирландии) уже ощущают давление на сети и генерацию, что приводит к очередям на техприсоединение, локальным ограничениям и росту тарифных рисков.
Для компаний это означает: важно знать физические регионы размещения ИИ-кластеров и «грязность» локальной сетевой смеси (carbon intensity), а также учитывать переносы вычислений во времени (carbon-aware scheduling).
Вода и охлаждение: скрытая цена
Рост ИИ-нагрузок увеличивает водный след дата-центров через испарительное охлаждение и производство электроэнергии. Для ИИ уже публикуют оценки воды на «один запрос», но такие метрики нужно читать критически: они часто не учитывают косвенную воду и сильно зависят от места и времени суток. Подробнее о водной составляющей — в исследовании из команды Шаолэя Жэня и в нашем разборе по ссылке в конце.
Что будет дальше до 2030 года
Тренд очевиден: больше инференса, больше мультимодальности и контекстов, больше специализированных ускорителей и более «горячих» регионов размещения.
В базовом сценарии крупнейшие провайдеры будут наращивать закупки безуглеродной электроэнергии (PPA/GPPA) и строить более эффективные ЦОДы (жидкостное охлаждение, снижение PUE), но суммарный спрос на кВт·ч всё равно вырастет. Ключевая неопределённость — темпы внедрения «эффективного ИИ» (меньшие модели, дистилляция, квантизация, спарсити) и регулирование (нормы раскрытия и энерго-водных метрик, локальные лимиты на подключение).
Методологические риски и почему цифры так расходятся
- Мало публичных данных: не раскрывают GW/GWh по ИИ отдельно от прочих нагрузок, путают локационные и рыночные метрики выбросов, игнорируют воду «вверх по цепочке».
- Сильная зависимость от предположений: доля утилизации чипов, структура токенов на запрос, глубина кэширования, размеры/варианты моделей, температура и влажность площадки.
- Эффективность != экономия: эффект Джевонса — падение удельной энергии на запрос приводит к росту общего трафика.
Практические шаги для компаний
- Измеряйте: счётчик «энергия на 1k токенов/запрос», «вода на запрос/час инференса», доля low-carbon часов. Внедрите сквозной трекинг от маршрутизации запросов до слоя модели.
- Правильный выбор модели: «меньшая модель по умолчанию»; дистилляция/LoRA; агрессивная квантизация (8/4-бит); спарсити/MoE; ранняя остановка генерации; ограничения на контекст.
- Экономия на архитектуре: кэширование KV и RAG-результатов, запросы-батчи, асинхронная запись, дедупликация документов в пайплайне.
- Планирование по углероду: carbon-aware маршрутизация (перенос неинтерактивных задач в часы низкой углеродной интенсивности), распределение по регионам с чистой сетевой смесью.
- Контракты на «чистую» энергию: PPA/GPPA в регионах, где у вас наибольшая утилизация; по возможности — физическая привязка генерации.
- Требуйте прозрачности от провайдера: отдельные отчёты по ИИ (inference vs. training), метрики PUE/WUE по площадкам, локационные выбросы, доля безуглеродной энергии почасово.
Что делать редакциям, продуктам и ИИ-стартапам уже сегодня
- В интерфейсе — лимитируйте длину ответов и контекста по умолчанию; предлагайте «сжатые» режимы.
- На стороне бэкенда — внедрите A/B-контроль «малые модели + кэш» против «большие модели без кэша»; фиксируйте экономию в кВт·ч/1000 ответов.
- Для мультимодальности — не прогоняйте весь контент через LLM: используйте специализированные дешёвые детекторы/векторные индексы как фильтр.
- В снабжении — размещайте вычисления в регионах с низкой углеродной интенсивностью сети и адекватной водной доступностью.
Вывод
Электричество, необходимое для «содержания» ИИ, растёт и будет расти, прежде всего из-за инференса. ЦОДы становятся эффективнее, но эффект Джевонса съедает выигрыш. Лучшее, что можно сделать сейчас: мерить удельные метрики, выбирать «достаточно маленькие» модели, агрессивно оптимизировать пайплайны, заключать «чистые» энергетические контракты и требовать от поставщиков честной отчётности по ИИ-нагрузкам. Это снижает кВт·ч и счёт в деньгах без потерь для пользователей.
Источники
- IEA — Energy and AI (обзор и прогнозы)
- IEA — новости и цифры по росту потребления ЦОД
- CarbonBrief — 5 графиков про энергию ЦОД и ИИ
- Irish Times — 22% электроэнергии Ирландии ушло на ЦОД в 2024
- Google Environmental Report 2024
- Google — методика оценки «энергии на запрос» (инференс)
- Microsoft Environmental Sustainability Report 2024 (PDF)
- Alex de Vries — оценка доли ИИ в потреблении ЦОД (Joule, 2025; обзор)
- Wired — разбор исследования de Vries (контекст и ограничения)
- WRI — почему прогнозирование спроса ЦОД столь неопределённо
- Li et al. — «Making AI Less Thirsty» (водный след ИИ)
- The Verge — критика «воды на запрос» и вопросы методики
- AILYNX — «Сколько воды пьёт ваш ИИ?» (редакционный разбор)